
An AI ‘Archivist for Good’ Approach to the Epstein Files
Also inside: NY-12 debate hosted by COURIER and MeidasTouch


Hi y’all - I’m Josh Levine, Co-Founder and CEO of Thorian AI. In a modern technology ecosystem that often frames AI as a zero-sum exercise, we deploy AI-powered data tools to reinforce the social contract between citizens, companies, and the institutions that serve them. Thorian operates under a framework of ‘Principled AI’, which guides us to build applications and pursue data projects that are net positive for society.
More on that below, but first…
Digital ad spending, by the numbers:
FWIW, U.S. political advertisers spent around $16.8 million on Facebook and Instagram ads last week. Here were the top ten spenders nationwide:
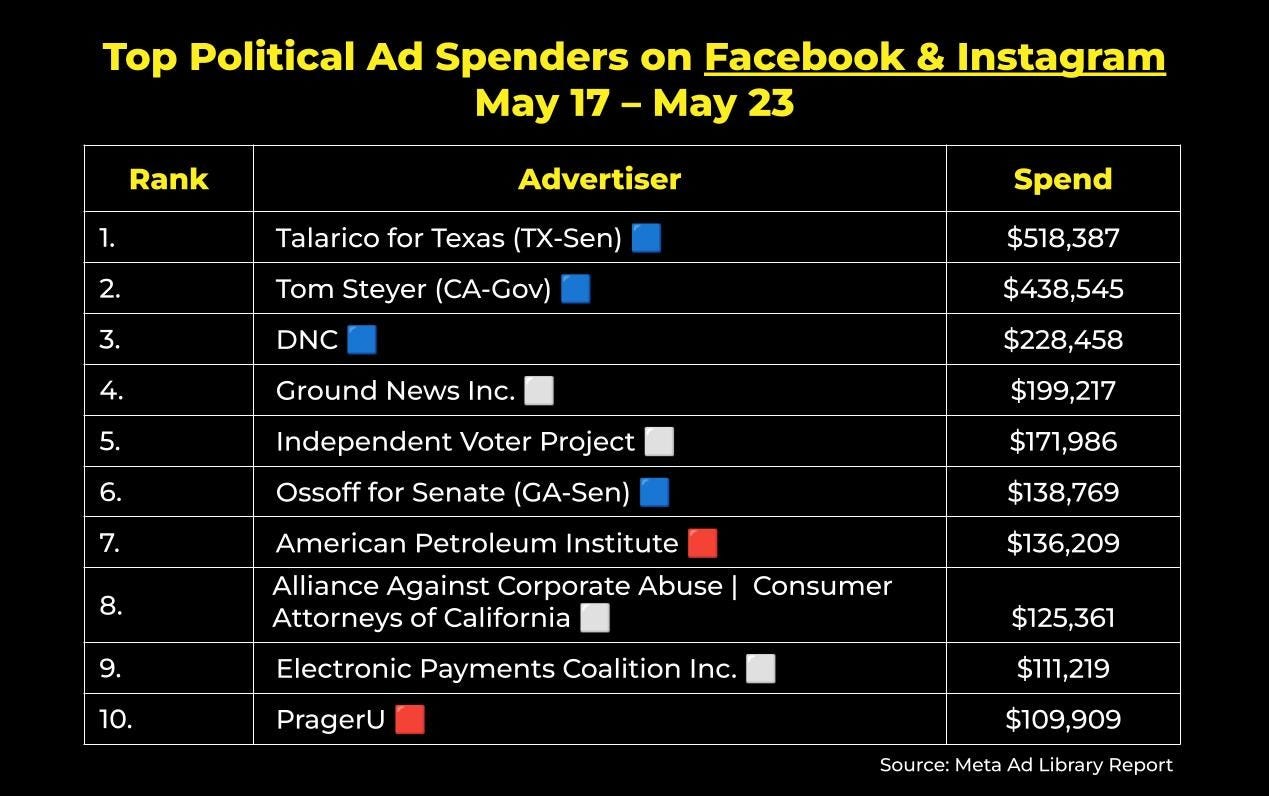
Team Steyer learned last week that everything’s bigger in Texas — including war chests (or at least how much a campaign might shell out any given week). James Talarico topped the Meta spending charts ahead of his official general election kickoff, happening today.
With attention starting to shift toward the November ballot, Alliance Against Corporate Abuse is gearing up for a showdown with Uber as the tech platform advances a ballot measure aimed at limiting its liability when customers are harmed.
Meanwhile, political advertisers spent around $17.7 million on Google and YouTube ads last week. These were the top ten spenders nationwide:
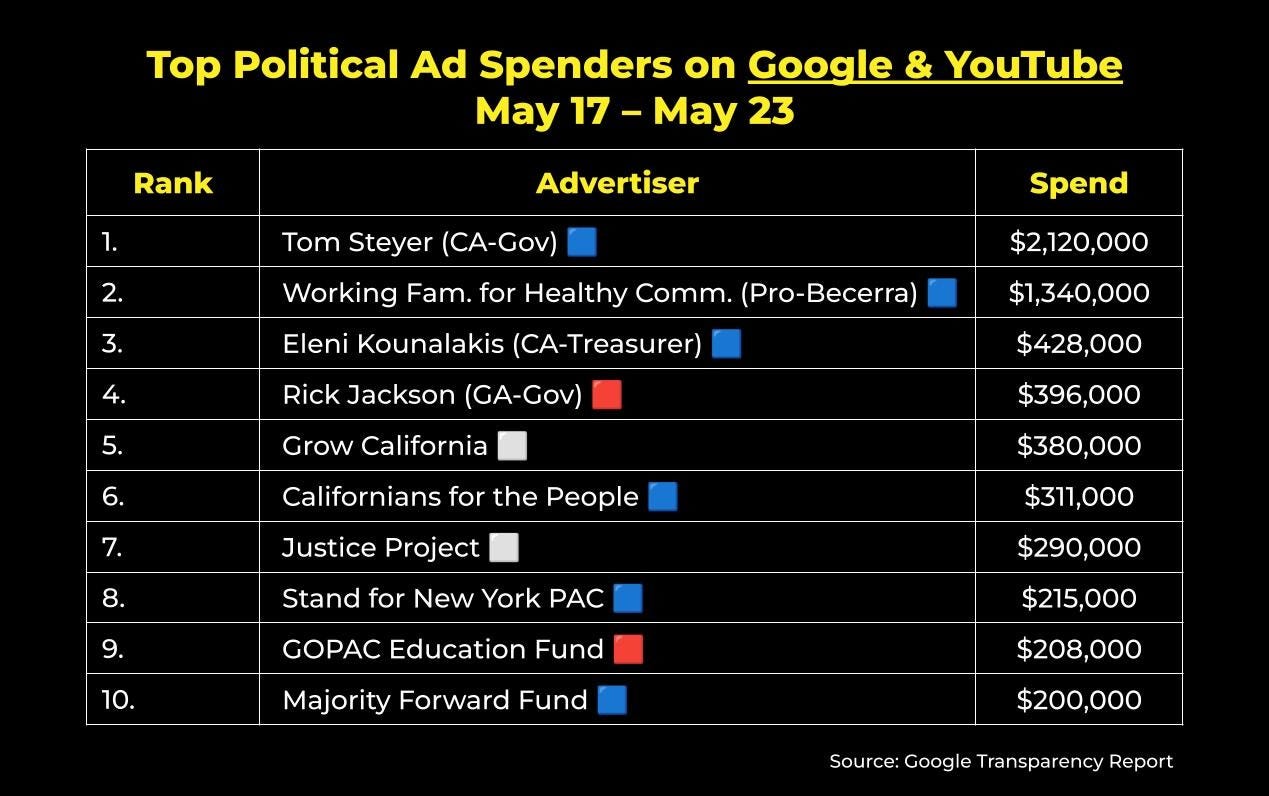
Hey Siri, play “The Final Countdown” by Europe. With Californians headed to the polls (or very slowly returning the vote-by-mail ballots automatically sent to all active registered voters in the Golden State - yay democracy!) ahead of Tuesday’s primary, we’re entering the home stretch of charts that look like this.
And with June fast approaching, we’re starting to see one of the buzziest primaries (NY-12) start to gain some traction: Mike Bloomberg’s Stand for New York PAC supporting Micah Lasher, current New York Assemblymember and congressional hopeful, came in at number 7.
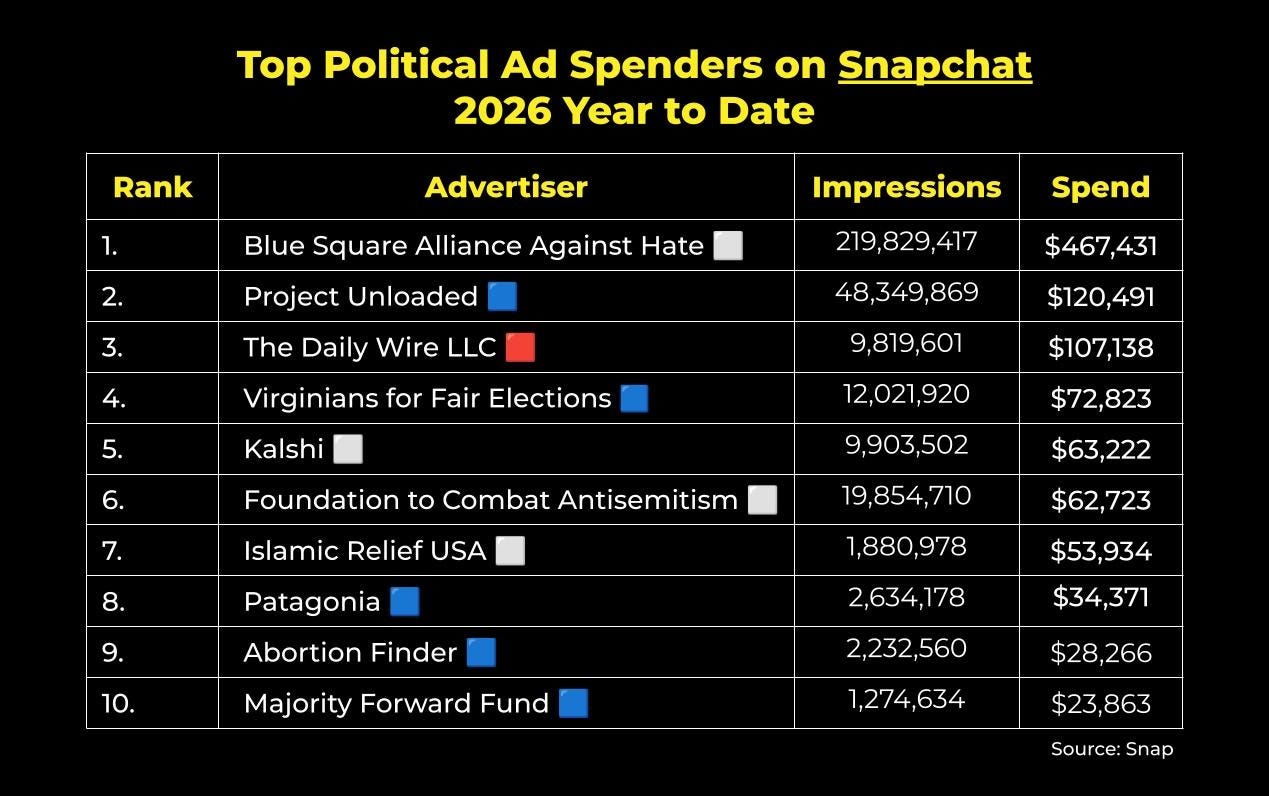
We’re fast-forwarding through X (formerly Twitter) until there’s new data to share and rounding out this week’s charts with Snapchat. To date, political advertisers in the U.S. have spent just over $1.7M on Snap ads in 2026:
An AI ‘Archivist for Good’ Approach to the Epstein Files
President Nixon was impeached by the House of Representatives 52 years ago this summer. During the impeachment hearings, members of Congress reviewed evidence of the President’s crimes, concluding that his actions violated both federal law and the public trust. While Congress ultimately put the final nail in the coffin of the Nixon presidency, uncovering the administration’s crimes required the professionalism of law enforcement, the dogged pursuit of truth from investigative reporters, and a public that demanded accountability.
Conditions in our current democracy look a little different from the Nixon years: Institutions designed to protect the public from government overreach, like the FBI and Department of Justice, have become increasingly politicized, and control over major media organizations has consolidated in the hands of a small number of wealthy and politically-connected people.
On the other hand, access to information has never been more distributed. Technology now makes it easier than ever for members of the public to independently compile, analyze, and share information. When every whistleblower has a platform, and firsthand accounts of every event can reach millions through social media, total control over the public narrative is nearly impossible - as long as the public has a will to pursue the truth.
Of course, the modern information ecosystem has its downsides. The same systems that democratize access to information can also be distorted by fake expertise, AI slop, data tampering, and the sheer volume of content competing for declining attention spans.
With so much information at our fingertips, the ability to find patterns, see through falsehoods, and extract meaning has become both more difficult and more essential. Whenever possible, individuals, journalists, and companies can overcome this complexity by serving as archivists, maintaining an unvarnished, auditable record of the truth so the public can continue holding powerful institutions accountable.
In addition to traditional tools like interview notes and secure document rooms, modern archivists working in the public interest use data science, web scraping, and large language models to make information more accessible. The next Woodward and Bernstein may look very different from the reporters of the 70s.
Thorian AI, the company I co-founded, specializes in using technology to parse large and complex datasets. We partner with mission-aligned organizations to find data and make it accessible. Recently, we did exactly that in partnership with COURIER. We worked together to break down the Epstein Files, taking one of the biggest and most difficult-to-use public datasets in the current political ecosystem and making it accessible.
Why the Epstein Files
The DOJ’s botched release of the Epstein Files presents the perfect opportunity to leverage technology for archival work in service of the public.
Despite Congress’ passage of the bipartisan Epstein Files Transparency Act, which created a legal requirement for the release of the files, the DOJ has only partially complied. Roughly 1.24 million files have been made available for download through the DOJ website, but the archive is extraordinarily difficult to use. The files are poorly labeled, inconsistently redacted, and presented in formats that are difficult to navigate. In some cases, victims’ names and nude photos remain visible, while other relevant information is obscured. Numerous files that arguably fall under the scope of the Act have not been released at all. Of the files that have been released, some have been removed and re-added multiple times. In other cases, the government has inexplicably changed its redactions over time, with some previously-available files becoming completely blacked out in later iterations.
This is exactly the kind of situation ripe for the work of a data-focused archivist. While the files’ current presentation is inconsistent with public transparency, advanced data techniques and artificial intelligence can be used to parse, tag, and organize the entities within them so the public can understand what’s happening. That work is essential. If the public does not know what’s in the files, it cannot hold people accountable.
How we parsed the Epstein Files
Working with COURIER, Thorian AI has produced the most detailed and fully-parsed database of the Epstein Files available to the public. We extracted every piece of usable data across the entirety of the 1.24 million files - hundreds of thousands of unique names, places, accounts, and dates, all spread across a vast and otherwise impermeable surface.
The process wasn’t easy. We had to overcome numerous challenges, and there were four factors that contributed to making this process more difficult.
First, the structure of the files themselves. Most of the Epstein files exist as PDF scans of images, flattened and stripped of a large portion of their metadata. To recover as much data as possible, we needed a system capable of combining Optical Character Recognition (OCR) extraction of information with AI-assisted modeling. The government’s searchable OCR results were lacking, so we re-extracted data from the files ourselves as the project evolved.
Second, the way that the files are stored on the DOJ’s website. The site contains disorganized collections of PDFs, jumbled randomly across different buckets. To make matters more challenging, accessing each individual file requires users to go through age verification, which means clicking on a button every time they want to look at something.
Third, the way the government keeps shifting the contents of the files. The collections and files have not been static. Hundreds of thousands of files have disappeared for months at a time. More than 65,000 files went through multiple shifts in their redaction schemas, meaning that information that was readable in one version ended up being redacted in another. These changes have occurred without warning, forcing us to vigilantly and continuously monitor the archives.
The immense volume of the files was an additional hurdle to overcome. Given the limitations of other approaches, we knew our extraction strategy needed to utilize AI in order to obtain as much data as possible. However, we also had to work within the technical limitations of current large language models. Even with recent improvements to context windows (the amount of data that can be parsed by a model at one time), the biggest models can only handle about 1000 pages of these documents on their own at a time. Given the structural challenges described above, a brute force AI approach would have required constant data reingestion, making the process extremely inefficient.
The fourth and final challenge has to do with the contents of the files themselves. Given the nature of Epstein’s crimes, a large number of the files detail the monstrous behaviour of him and his associates. AI models generally have guardrails that block the kind of content present in the files, threatening to blunt comprehensive analysis of the cache.
Many of the (still very good) attempts to bring transparency to the Epstein Files struggle with these challenges. Some projects achieve high quality data extraction, but do so at the expense of volume - they use the government’s search filters to identify individuals and entities of interest and then parse a smaller volume of files before making them accessible through a public-facing interface. This pathway can be very useful if you’re looking to learn about people you already know exist within the files, like Donald Trump or Howard Lutnick. However, the method falls short; users will end up with an incomplete picture of the Epstein story because search results are not grouped by subject or connected chronologically. When full story arcs are obscured by the DOJ website’s current formatting, it’s difficult to do the sleuthing needed to uncover new names and angles that have not already been in the news.
Other groups struggle with the extraction itself. Their attempts to parse the entire corpus of the files have fallen short, likely due to OCR issues and compute constraints.
How we cracked the Epstein Files and what comes next
Our company specializes in solving exactly these kinds of problems, so the methods we used in this case are, for the most part, a professional secret. In broad terms, our approach relied on a system of AI agents with differing levels of expertise operating as a unit to autonomously manage OCR processes, extract and tag data, and put the data into context with the rest of the files. Rather than using frontier models, we mixed our agents, consistently using the smallest possible open-source model for each individual task. This allowed us to keep costs manageable, especially since we run our extraction system on a regular basis, sometimes for weeks at a time.
One place where our data principles helped us was with the shifting versions of the files. Because our team is constantly looking for big public datasets on which we can run experiments, we started downloading the Epstein Files as soon as they were released. Therefore, we have every version of every file in the cache, allowing us to provide better insight around how documents and redactions have changed over time.
On the front end, we put together an interface that allows users to conduct text searches, analyze files by tagged person/entity, explore specific topics, and compile chronological stories that exist within the files. Upcoming features include LLM-enabled search, image search, and other custom topic features.
To close, we ask that you:
Check out the site and do some digging
Surface story tips and ideas for additional ways you’d like to see the data displayed
Share the site with your contacts.
In today’s technological moment, members of the public can also serve as archivist-investigators. So let’s push the story forward and bring light to the darkness of the Epstein chapter in our country.
Please note: Thorian AI is a paid vendor of COURIER.
That’s it for FWIW this week. This email was sent to 25,815 readers. If you enjoy reading this newsletter each week, would you mind sharing it on X/Twitter, Threads, or Bluesky? Have a tip, idea, or feedback? Reply directly to this email.

The Future of the Democratic Party is on the Ballot
Join COURIER and MeidasTouch on Wednesday, June 10 at 6:30 PM ET for the NY-12 Primary Debate, featuring George Conway, Jack Schlossberg, Alex Bores, Laura Dunn, Nina Schwalbe, and Micah Lasher.
In one of the country’s most closely watched congressional races, candidates will debate the future of the Democratic Party at a moment of growing frustration, generational change, and political upheaval.
Candidates will debate the issues shaping the 2026 midterms, including affordability and housing, immigration, corruption and money in politics, democracy reform, climate, AI regulation, and American leadership in a second Trump era.
Register now to watch live.
 | A guest post by
|